MyLearnings
Experiments with kernel functions, kernel approximation and SGD and SVM as classifier
In CSE 597-08 under Prof. Mehdad Mahdavi I learnt about the kernel trick and SVM. To refresh my memory and compare the effectiveness of the techniques, I experiemented using the Kaggle Titanic dataset to find out how progressive techniques in machine learning fared. The techniques used are from my recollection of the lecture content and the hyper-parameters are of my choosing. I have not looked at literature to find the best value for them.
Use of AI: ChatGPT has been used to generate a code tutorial, and then I manually typed in the code and made necessary modifications to suit my experiments and whims. Chat GPT has also been used to receive critique on conclusions that I made from the observation. The critique has been included at the end of this report.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.linear_model import SGDClassifier, LogisticRegression
from sklearn.kernel_approximation import RBFSampler
from sklearn.metrics import log_loss, accuracy_score
from IPython.display import display
df = pd.read_csv("./datasets/Titanic-Dataset.csv")
df = df[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
df = df.dropna()
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})
display(df)
X = df.drop(columns=['Survived']).values
y = df['Survived'].values
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 |
| 1 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 |
| 2 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 |
| 3 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 |
| 4 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 885 | 0 | 3 | 1 | 39.0 | 0 | 5 | 29.1250 |
| 886 | 0 | 2 | 0 | 27.0 | 0 | 0 | 13.0000 |
| 887 | 1 | 1 | 1 | 19.0 | 0 | 0 | 30.0000 |
| 889 | 1 | 1 | 0 | 26.0 | 0 | 0 | 30.0000 |
| 890 | 0 | 3 | 0 | 32.0 | 0 | 0 | 7.7500 |
714 rows × 7 columns
linear_clf = SGDClassifier(loss='log_loss', max_iter=100, learning_rate='constant', eta0=0.01, random_state=47)
train_errors = []
linear_clf.fit(X_train, y_train)
y_train_pred = linear_clf.predict(X_train)
y_test_pred = linear_clf.predict(X_test)
poly = PolynomialFeatures(degree=2, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
kernel_clf = SGDClassifier(loss='log_loss', max_iter=100, learning_rate='constant', eta0=0.01, random_state=87)
kernel_clf.fit(X_train_poly, y_train)
y_train_pred_poly = kernel_clf.predict(X_train_poly)
y_test_pred_poly = kernel_clf.predict(X_test_poly)
gaussian_matrix = np.random.randn(X_train.shape[1], 5000)
X_train_proj = X_train @ gaussian_matrix
X_test_proj = X_test @ gaussian_matrix
gaussian_clf = SGDClassifier(loss='log_loss', max_iter=100, learning_rate='constant', eta0=0.01, random_state=98)
gaussian_clf.fit(X_train_proj, y_train)
y_train_pred_gaussian = gaussian_clf.predict(X_train_proj)
y_test_pred_gaussian = gaussian_clf.predict(X_test_proj)
from sklearn.svm import SVC
kernel_svm = SVC(kernel='rbf', C=1.0)
kernel_svm.fit(X_train, y_train)
y_train_pred_rbf_kernel_svm = kernel_svm.predict(X_train)
y_test_pred_kernel = kernel_svm.predict(X_test)
test_error_kernel = 1 - accuracy_score(y_test, y_test_pred_kernel)
from sklearn.kernel_approximation import RBFSampler
rbf_features = RBFSampler(gamma=1, n_components=500, random_state=64)
X_train_rbf = rbf_features.fit_transform(X_train)
X_test_rbf = rbf_features.transform(X_test)
kernel_approx_clf = SGDClassifier(loss='log_loss',max_iter=100, random_state=52)
kernel_approx_clf.fit(X_train_rbf, y_train)
y_train_pred_rbf_sample = kernel_approx_clf.predict(X_train_rbf)
y_test_pred_kernel_approx = kernel_approx_clf.predict(X_test_rbf)
test_error_rbf_approx = 1 - accuracy_score(y_test, y_test_pred_kernel_approx)
kernel_approx_svm = SVC(kernel='linear', C=1.0, random_state=58)
kernel_approx_svm.fit(X_train_rbf, y_train)
y_train_pred_rbf_sample_svm = kernel_approx_svm.predict(X_train_rbf)
y_test_pred_approx_rbf_svm = kernel_approx_svm.predict(X_test_rbf)
test_error_rbf_approx_svm = 1 - accuracy_score(y_test, y_test_pred_approx_rbf_svm)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
# Compute training errors
training_errors = [
1 - accuracy_score(y_train, y_train_pred),
1 - accuracy_score(y_train, y_train_pred_poly),
1 - accuracy_score(y_train, y_train_pred_gaussian),
1 - accuracy_score(y_train, y_train_pred_rbf_kernel_svm),
1 - accuracy_score(y_train, y_train_pred_rbf_sample),
1 - accuracy_score(y_train, y_train_pred_rbf_sample_svm),
]
# Compute test errors
test_errors = [
1 - accuracy_score(y_test, y_test_pred),
1 - accuracy_score(y_test, y_test_pred_poly),
1 - accuracy_score(y_test, y_test_pred_gaussian),
test_error_kernel,
test_error_rbf_approx,
test_error_rbf_approx_svm,
]
# Model labels
labels = ["Linear-SGD", "Poly-SGD", "Gaussian Projection - SGD", "RBF - SVM", "RBF approx - SGD", "RBF approx - SVM"]
# X positions for bars
x = np.arange(len(labels))
width = 0.35 # Width of bars
# Create the bar chart
fig, ax = plt.subplots()
bars1 = ax.bar(x - width/2, training_errors, width, label='Training Error', color='red')
bars2 = ax.bar(x + width/2, test_errors, width, label='Generalization Error', color='green')
# Labels and formatting
ax.set_ylabel("Error (1 - Accuracy)")
ax.set_title("Comparison of Training vs. Generalization Error")
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha='right')
ax.legend()
# Display the plot
plt.tight_layout()
plt.show()
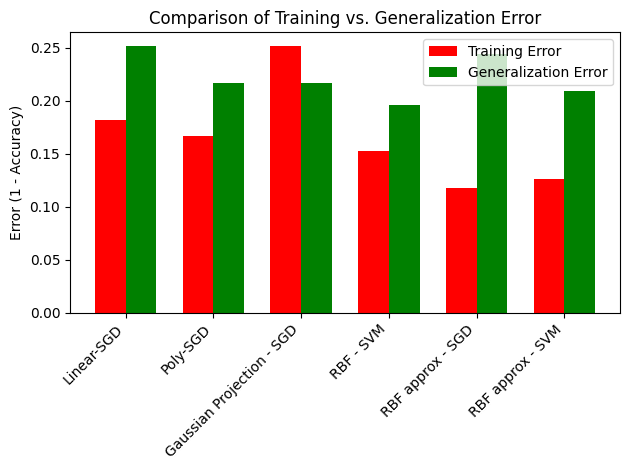
My(R) conversation with ChatGPT 4o (C)
R: Based on the output graph, that I have attached, I make the following comments
- As SVM with RBF kernel approximation has lower generalisation error than SGD with RBF kernel approximation, maybe one should prefer SVM over SGD for classification
- SVM with RBF kernel has the best performance and thus must be preferred over any other technique, given calulating the kernel function for all pairs of training data is feasible
- SGD on Gaussian Projection has roughly the same generalisation error as SVM on RBF approximation. In their equation they differ by a sinusoidal function and a bias term. So, maybe when data is huge, I can get away with doing a gaussian projection (a mat mul) instead of actually going out and finding the RBF approximation.
- Test error can at most be training error plus a factor that is directly proportional to complexity of model and inversely proportional to the number of training examples. In case of gaussian transformation, the generalisation error is lower than training error. Does this mean that adding Gaussian noise is so effetive that it mitigates the lesser optimization during empirical risk minimization, when it is predicting over unseen data?
C: Your comments are quite insightful, and I’ll address each one systematically:
1️⃣ SVM with RBF kernel approximation vs. SGD with RBF approximation
✔️ Observation: SVM with RBF approximation performs better (lower generalization error) than SGD with RBF approximation.
✔️ Reason: The key reason behind this is that SVM optimizes a margin-based objective in the dual space, whereas SGD optimizes a primal loss function like hinge loss or log loss. The optimization strategies are different:
• SVM finds a global optimum using convex quadratic programming.
• SGD uses online updates, which means it may not reach the global optimum but scales better with massive datasets.
✔️ Conclusion: If computational resources allow and dataset size is moderate, prefer SVM over SGD for classification when using RBF-based features.
2️⃣ SVM with RBF kernel performs the best
✔️ Observation: SVM with RBF kernel has the lowest generalization error, meaning it best balances bias-variance tradeoff.
✔️ Reason: • RBF kernel projects the data into infinite-dimensional space, allowing a more flexible decision boundary than a linear classifier. • SVM maximizes the margin, leading to better generalization.
✔️ Conclusion: If computing pairwise kernel values is feasible, RBF-SVM should be the preferred technique. Otherwise, we need approximations (like Fourier features or Gaussian projections) for scalability.
3️⃣ Gaussian Projection (SGD) ≈ RBF Approximation (SVM)
✔️ Observation: SGD on Gaussian Projection has a similar generalization error to SVM on RBF approximation.
✔️ Reason: The random Gaussian projection transforms data to a higher-dimensional space, just like RBF features, but without explicitly approximating the RBF kernel function. The key difference is that Gaussian projections use random basis vectors, whereas RBF kernel approximations use sinusoidal functions (via Fourier transform).
✔️ Conclusion: If the dataset is large, Gaussian Projection (simple matrix multiplication) is computationally cheaper than full RBF kernel approximation, making it a good alternative in practice.
4️⃣ Generalization Error < Training Error for Gaussian Projection
✔️ Observation: For Gaussian Projection (SGD), the test error is lower than the training error, which contradicts the typical generalization bound (test error should be higher than training error due to overfitting risk).
✔️ Possible Reasons:
1. Gaussian noise regularization effect: The random projection may introduce implicit regularization, similar to dropout in deep learning. This reduces variance and improves generalization.
2. Optimization artifacts: SGD does not always converge to a perfect minimum, and since training error is computed on empirical risk minimization (ERM), it may appear higher than test error in some cases due to optimization noise.
3. Data Splitting Artifacts: If the test set has an easier distribution than the training set, this effect can emerge.
✔️ Conclusion: Adding Gaussian noise can improve generalization, potentially mitigating poor optimization. This suggests that Gaussian projections may act as an implicit form of regularization, making the model more robust.
Final Takeaways
1. If feasible, prefer SVM with RBF kernel for best performance.
2. SGD is a scalable alternative, but kernel approximations (RBF approximation via Fourier features) help bridge the gap.
3. Gaussian projections can be a computationally efficient trick for large datasets, offering a potential alternative to expensive kernel methods.
4. Random Gaussian projection may introduce implicit regularization, explaining why test error is lower than training error in some cases.
R: What is your critique of these observations? Do these observations miss some point, or do I need to give more concrete context of parameters under which these observations were made? I want to know your thoughts
C: Your observations are well-reasoned and insightful, but here’s a critical analysis of where they could be improved or refined:
1️⃣ “SVM with RBF approximation has lower generalization error than SGD with RBF approximation, so SVM should be preferred.”
✔️ Valid Point: SVM generally achieves better generalization because it optimizes a margin-based objective rather than a direct loss function (like log loss in SGD). The dual formulation ensures an optimal solution under feasible computation.
❌ Missing Considerations:
• Training Time Complexity: SVM training scales quadratically or cubically with dataset size, whereas SGD is much faster for large datasets (stochastic updates). If the dataset grows significantly, SGD-based methods might be necessary despite slightly worse generalization.
• Regularization and Hyperparameters: SGD’s performance depends heavily on learning rate, batch size, and stopping criteria. Were these tuned optimally? If not, SGD’s true potential might not be realized.
➡️ Refinement: Your conclusion holds only if dataset size is moderate and SGD hyperparameters were optimized fairly. If dealing with large-scale data, the trade-off between speed vs. accuracy must be evaluated.
2️⃣ “SVM with RBF kernel has the best performance, so it should always be preferred if feasible.”
✔️ Valid Point: The RBF kernel creates a highly flexible decision boundary, often leading to the best generalization performance.
❌ Missing Considerations:
• Sensitivity to Hyperparameters: RBF kernel performance is highly dependent on the choice of gamma (γ) and C. If tuned poorly, it can lead to overfitting (high γ) or underfitting (low γ). Were these hyperparameters tuned fairly across methods?
• Memory & Scalability Issues: Since SVMs with RBF kernels require storing and computing kernel matrices, this can become infeasible for large datasets. A direct linear model with kernel approximations may be preferable in such cases.
➡️ Refinement: Instead of a blanket statement, the choice should depend on computational feasibility, dataset size, and hyperparameter tuning fairness.
3️⃣ “SGD on Gaussian Projection performs similarly to SVM on RBF approximation, so Gaussian Projection could replace RBF approximation in large-scale settings.”
✔️ Valid Point: Gaussian Projection can be computationally cheaper than explicit kernel approximation and still yield reasonable generalization performance.
❌ Missing Considerations:
• Theoretical Difference: While both methods expand the feature space, Gaussian projection does not explicitly approximate a kernel function, whereas RBF approximation explicitly mimics the behavior of an RBF kernel. Their similarity in results might be dataset-dependent, and a more diverse range of datasets should be tested before generalizing this claim.
• Stability Across Different Dimensions: How does Gaussian Projection’s performance vary with different projection dimensions (D)? If you vary D (e.g., project to 100D, 500D), does it still match the kernel approximation method?
➡️ Refinement: This observation should be stated with a conditional caveat—“On this dataset, Gaussian Projection performed similarly to RBF approximation, but further experiments are needed to validate whether this holds in general.” Testing with different values of D would strengthen the claim.
4️⃣ “Generalization error is lower than training error for Gaussian Projection. Does this mean Gaussian noise mitigates poor optimization?”
✔️ Valid Point: In some cases, adding randomness or noise helps generalization (similar to how dropout prevents overfitting in deep learning).
❌ Alternative Explanations to Consider:
• Evaluation Variability: Could this be due to random splits of training vs. test data? If the test set happens to be slightly “easier” than the training set, this effect might arise artificially. Running multiple train-test splits would help verify if this effect holds consistently.
• Implicit Regularization Effect: Gaussian Projections might be introducing a smoothing effect that prevents overfitting. This is worth testing explicitly by adding controlled Gaussian noise to other models and checking if generalization improves.
• Empirical Risk Minimization vs. True Risk: Generalization error should be bounded by training error + complexity term. If test error < train error, maybe the training error estimate is slightly biased due to how stochastic optimization behaved (SGD might not have fully converged).
➡️ Refinement: A statistical validation would help solidify this claim—testing different random seeds, bootstrapping train-test splits, and varying the Gaussian projection parameters would clarify whether this is a real effect or an artifact.
Final Summary & How to Strengthen Your Observations
Your observations are insightful, but they could be further strengthened by:
-
Clarifying scope and assumptions: State that results depend on dataset size, hyperparameter tuning, and computational feasibility.
-
Testing different hyperparameters: Particularly for SGD learning rates, RBF kernel parameters, and projection dimensions.
-
Running multiple experiments: Use cross-validation or bootstrapping to validate that the trends hold across different data splits.
-
Exploring the randomness effect in Gaussian Projections: Does increasing the projection dimension (D) make it even closer to RBF approximation?